


Increase 10x API Read speed with cache using Redis
Cache aside strategy - Edition #19

Hey, I'm Marco and welcome to my newsletter!
As a software engineer, I created this newsletter to share my first-hand knowledge of the development world. Each topic we will explore will provide valuable insights, with the goal of inspiring and helping all of you on your journey.
In this episode I show you how to introduce a caching system like Redis by showing you how I did it for the Magic Link-based authentication app.
You can download all the code shown directly from my Github repository: https://github.com/marcomoauro/magic-link-auth
👋 Introduction
Let us imagine that we have an API that aims to retrieve information from the database and then serve it up on a web page by the client.
Managing numerous database calls that repeatedly return very similar data can cause inefficiency problems because the database must be queried each time, consuming time and resources to obtain the same data over and over again.
Employing a cache can significantly alleviate this problem.
By caching frequently accessed data, subsequent requests for the same data can be served directly from the cache, reducing the need to query the database repeatedly. This speeds up response times and reduces the load on the database server, resulting in improved overall system performance.
What if the data are changed?
Cache introduces a trade-off between consistency and performance.
While caching can still improve performance by reducing the number of database queries, it may lead to stale data being served from the cache if updates are not properly synchronized.
In such cases, the system must balance the benefits of improved performance against the risk of serving outdated information. Strategies such as implementing cache invalidation mechanisms or setting shorter cache expiration times can help mitigate this trade-off by ensuring that the cached data remains relatively fresh.
It's essential to carefully evaluate the requirements of the application and the frequency of data updates to determine the most suitable caching strategy.
✅ Cache aside strategy
One possible strategy that can be used to introduce a caching mechanism is Cache Aside (or Lazy loading).
Data is cached only when it’s requested.
When an application requests data, it first checks if it is present in the cache, if present, it is returned directly from the cache otherwise it is retrieved from the source (e.g. a database), stored in the cache for future requests and then returned to the application.
in this way we obtain the following advantages:
Reduced latency: frequently requested data is cached, reducing the time required to access it compared to retrieval from slower storage systems such as databases.
Scalability: by reducing the load on back-end systems such as databases, the effective use of caching can help improve the overall scalability of the system.
Improved user experience: By serving frequently accessed data from the cache, users experience faster response times and smoother interactions with applications or websites. This leads to a more satisfying experience.
and disadvantages:
Waste of resources: when storing infrequently used data.
Data consistency: introduces the need to manage synchronization and cache invalidation to ensure that the data are up-to-date and consistent with the source.
👤 User caching in the Magic Link login app

Once the user has logged in, the client calls the server api GET /users/me to retrieve the user's data, here we can introduce a caching mechanism to avoid querying the database.
Let us introduce the mechanism using the following sequence diagram:
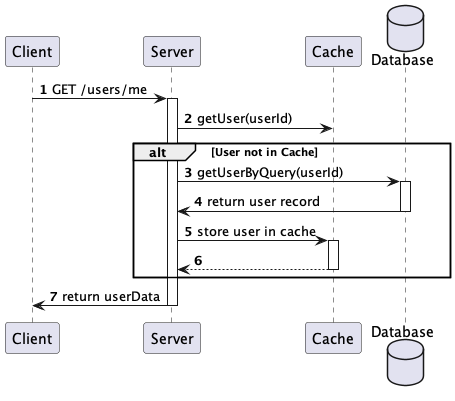
Client calls the server api GET /users/me.
Server checks if the user is in the cache.
Keep reading with a 7-day free trial
Subscribe to Implementing to keep reading this post and get 7 days of free access to the full post archives.