
Reduce Database Load with Bloom Filters
Probabilistic data structure - Edition #18

Hey, I'm Marco and welcome to my newsletter!
As a software engineer, I created this newsletter to share my first-hand knowledge of the development world. Each topic we will explore will provide valuable insights, with the goal of inspiring and helping all of you on your journey.
In this episode, I show you how the Bloom Filter data structure works and a possible implementation in Redis.
You can find the implementation here: https://github.com/marcomoauro/magic-link-auth/blob/main/src/usernameBloomFilter.js
🎲 Bloom Filter
A Bloom Filter is a probabilistic data structure, it allows representing a large amount of data using minimal memory. Its main feature is the ability to decisively state the absence of an element while admitting a certain probability for its presence.
It is represented by a finite array of bits, which are initially set to 0.
Unlike a HashMap, a Bloom filter doesn't save the actual values of the elements in the domain. Instead, it uses a bit array to store 0 and 1.

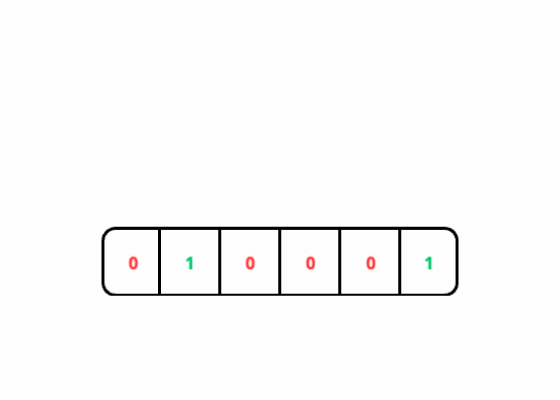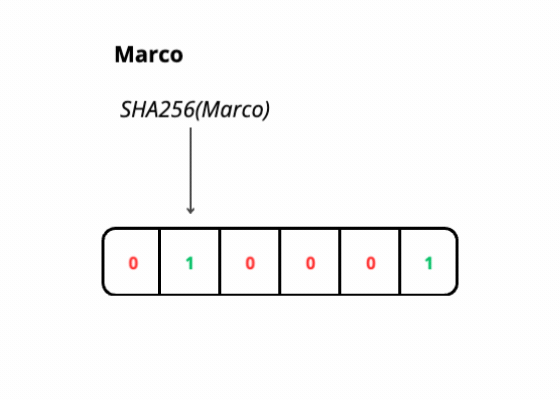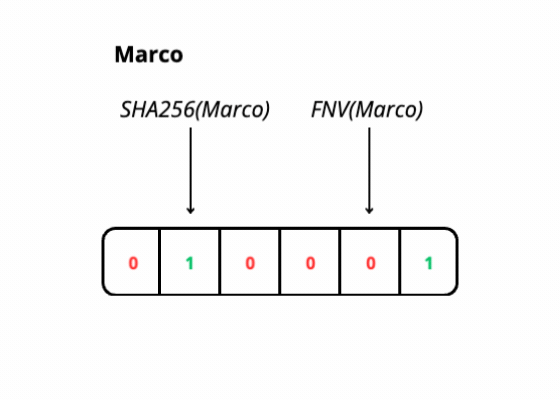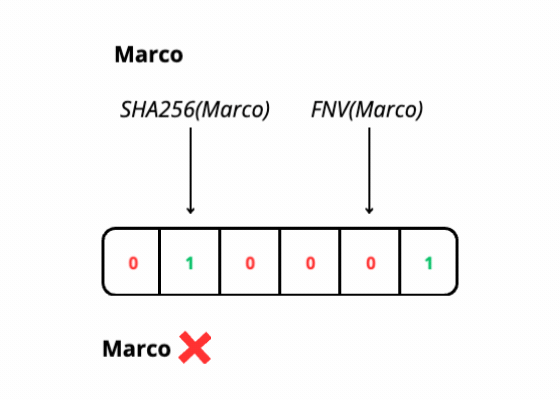
This efficiency is achieved through the use of K hash functions, which map elements onto a bit array. However, due to the finite size of the array and potential hash collisions, false positives can occur, indicating the presence of an element that isn't actually there.
The size cannot be changed once it has been established since doing so would result in the loss of references between bit array locations with hash function results. Changing the size requires recreating the filter all over again.
This efficiency makes Bloom Filters a top choice in many applications where fast operations and memory-saving are key priorities.
Hash functions
To ensure swift performance, it's essential for hash functions to distribute the domain values evenly across the filter and generate collisions infrequently. It's good practice to test the filter with elements from your domain to understand its performance and make adjustments as necessary.
Typical hash functions used are:
SHA256
MurmurHash
Fowler–Noll–Vo (FNV)
Search of an item
Keep reading with a 7-day free trial
Subscribe to Implementing to keep reading this post and get 7 days of free access to the full post archives.