

Reduce Database Load with Bloom Filters
Reduce Database Load with Bloom Filters
Probabilistic data structure - Edition #18

Hey, I'm Marco and welcome to my newsletter!
As a software engineer, I created this newsletter to share my first-hand knowledge of the development world. Each topic we will explore will provide valuable insights, with the goal of inspiring and helping all of you on your journey.
In this episode, I show you how the Bloom Filter data structure works and a possible implementation in Redis.
You can find the implementation here: https://github.com/marcomoauro/magic-link-auth/blob/main/src/usernameBloomFilter.js
🎲 Bloom Filter
A Bloom Filter is a probabilistic data structure, it allows representing a large amount of data using minimal memory. Its main feature is the ability to decisively state the absence of an element while admitting a certain probability for its presence.
It is represented by a finite array of bits, which are initially set to 0.
Unlike a HashMap, a Bloom filter doesn't save the actual values of the elements in the domain. Instead, it uses a bit array to store 0 and 1.
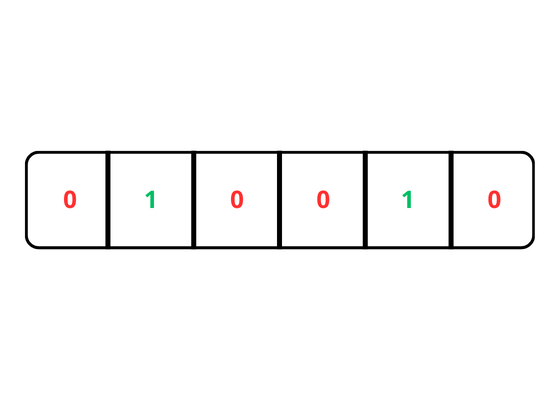
This efficiency is achieved through the use of K hash functions, which map elements onto a bit array. However, due to the finite size of the array and potential hash collisions, false positives can occur, indicating the presence of an element that isn't actually there.
The size cannot be changed once it has been established since doing so would result in the loss of references between bit array locations with hash function results. Changing the size requires recreating the filter all over again.
This efficiency makes Bloom Filters a top choice in many applications where fast operations and memory-saving are key priorities.
Hash functions
To ensure swift performance, it's essential for hash functions to distribute the domain values evenly across the filter and generate collisions infrequently. It's good practice to test the filter with elements from your domain to understand its performance and make adjustments as necessary.
Typical hash functions used are:
SHA256
MurmurHash
Fowler–Noll–Vo (FNV)
Search of an item
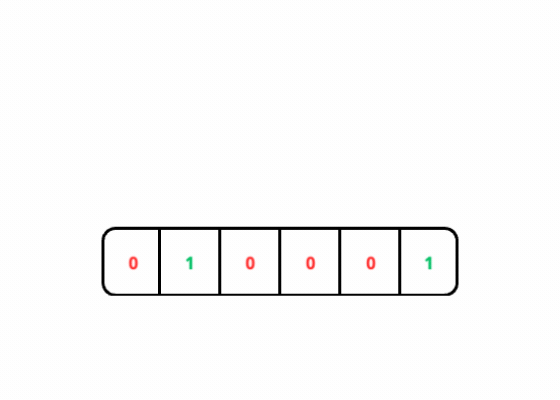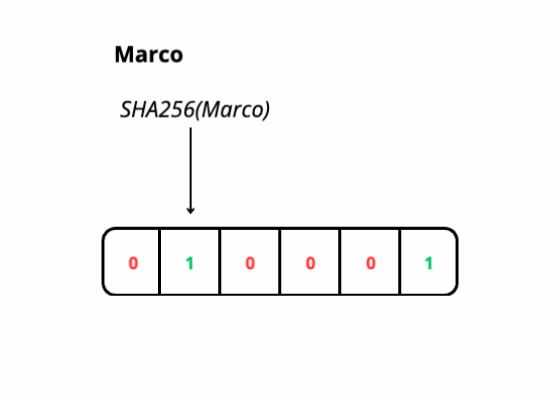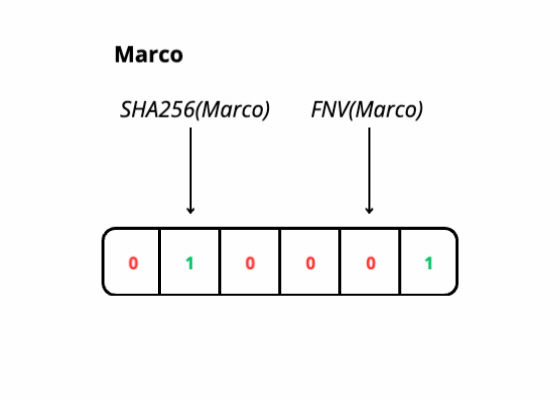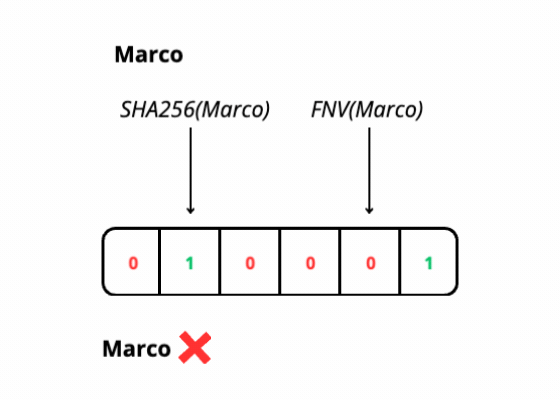
During the search operation, we use hash functions on elements from our domain, these functions give us the index in the bit array that we use to determine if the element is likely in the filter if all the corresponding bits are set to 1.
The operation has a time cost O(k) with k=number of hash functions, regardless of the number of stored elements. Since k is a value chosen at the filter design stage then the cost is constant.
This is because each search only has to check a few bits of the filter, those designated by the results of the hash functions.
However, since false positives may occur, some additional checks may be necessary, such as checking the presence of the value on the database.
Insertion of an item

During the insertion process, we use hash functions on the elements of our domain. These functions provide us with the index in the array of bits in which we must set the bit value to 1, with k hash functions we will have k indices to configure.
During insertion, Bloom filters maintain a constant time complexity O(k) with k=number of hash functions, since the value of k remains constant, the cost of insertion also stays constant. This is because, just as in searching, the only thing we do is calculate the array indices using hash functions and then set the corresponding bits to 1 and both of these actions require a constant cost.
Deletion of an item
In Bloom Filters, deletion of elements isn't supported because once a bit in the bit-array is set to 1, it cannot be unset without affecting other elements that may rely on the same bit. Since multiple elements could map to the same bit position through different hash functions, removing one element might accidentally remove others.
To support these operations, there are more sophisticated implementations such as Counting Bloom Filter and Double Hash Bloom Filter.
False positives

During retrieval in a Bloom filter, the probability of false positives changes based on parameters like filter size, number of hash functions and the ratio of inserted elements to total bits. Initially low, the probability increases as the filter saturates with more elements. Larger filters and more hash functions generally decrease false positives, while higher load factors can increase them. Balancing these factors is essential for efficient and accurate Bloom filter usage.
Application uses
load reduction in CDNs: there are webpages which are only requested once. According to the Akamai, 75% of the pages are One Hit Wonders.
For every request it ends-up ingesting an entry into the Bloom Filter. For every subsequent request, it checks whether this entry is present into the Bloom Filter. Only, if it’s present, then only the webpage is cached otherwise not.
Identify malicious URL in web browsers: Google Chrome used to use Bloom Filters, Only when Bloom-Filter declares that, an URL is probably malicious, then only it performs the fully blown check of verifying whether the URL is really malicious or not.
Since millions of malicious URLs are possible, over time they have changed their solution by migrating to other.
Database load reduction: Using a Bloom filter avoids unnecessary database queries when we want to know if an item does not exist. This method proves useful in scenarios such as selecting a user's nickname.
Due to hash function collisions, an item flagged as existing in the filter may exist in the database, so in this case it is necessary to always query the database.
💻 Bloom Filter implementation using Redis
To implement the Bloom filter, Redis BitMap data structure can be used.
The Bitmap in Redis is a sequence of bits where each bit can be set (1) or cleared (0). This data structure can be used to represent a set of binary values. Redis provides getbit and setbit primitives to read and write in the sequence with complexity O(1).
With this setup, a Bloom FIlter with 10 million bits can have a maximum weight of 1.31 megabytes, depending on the maximum value represented. If it is allocated from the beginning, it reaches this size; otherwise, it grows to a maximum of 1.31 megabytes if the largest bit is allocated.
I created the static class UsernameBloomFilter.js in JavaScript to implement the concept of Bloom Filter in the context of verifying the existence of usernames:
import Redis from 'ioredis';
import crypto from 'crypto';
import log from "./log.js";
const cache = new Redis(process.env.REDIS_URL);
export class UsernameBloomFilter {
static #cache_key = "username_bloom_filter_key";
static #size = 10_000_000;
static has = async (username) => {
log.info('UsernameBloomFilter::has', { username })
const indexes = this.#getIndexesFromHashing(username);
const found_result_bits = await Promise.all(indexes.map(async (index) => {
const get = await cache.getbit(this.#cache_key, index);
return get
})
);
const found = found_result_bits.every((bit) => bit === 1);
return found
}
static add = async (username) => {
log.info('UsernameBloomFilter::add', { username })
const indexes = this.#getIndexesFromHashing(username);
await Promise.all(indexes.map(async (index) => {
const add = await cache.setbit(this.#cache_key, index, 1);
return add
}));
}
static #getIndexesFromHashing(username) {
const indexes = [];
indexes.push(this.#sha256(username));
indexes.push(this.#fnvHash(username));
return indexes
}
static #sha256(username) {
const hashedUsername = crypto.createHash('sha256').update(username).digest('hex');
const hashedInt = parseInt(hashedUsername, 16);
return hashedInt % this.#size;
}
static #fnvHash(username) {
const FNV_PRIME = 16777619;
const OFFSET_BASIS = 2166136261;
let hash = OFFSET_BASIS;
for (let i = 0; i < username.length; i++) {
hash ^= username.charCodeAt(i);
hash *= FNV_PRIME;
}
const unsigned = hash >>> 0;
return unsigned % this.#size;
}
static printMemoryUsage = async () => {
const result = await cache.sendCommand(new Redis.Command('MEMORY', ['USAGE', this.#cache_key]));
console.log(result / 1_000_000, 'MB')
}
}The class exposes has and add methods to check for the existence and addition of usernames within the filter.
I used two hash functions, SHA256 and FNV, both return potentially very large values, to match the filter size I applied the “modulo” function (%) based on the array size, so the values I get are between 0 and the filter size.
👨💻 Let’s get down to practice
I introduced a bloom filter in the application that leverages the magic link to give the user the opportunity to choose their own nickname by checking its availability via a backend API that leverages only the Bloom Filter, does not use the database.

I created two new APIs:
GET /check-username: given a username check that it is available
POST /user/username: configures the username for the user
GET /check-username
I added the class UsernameBloomFilter.js to the /src folder.
I have added the checkUsernameAvailability method to the User.js model:
static checkUsernameAvailability = async (username) => {
const found = await UsernameBloomFilter.has(username)
if (!found) return true
// do a query on database because there may have been a collision of the hash functions in the Bloom Filter
try {
await User.get({username})
} catch (error) {
if (error instanceof APIError404) return true
throw error
}
return false
}It checks if the username is available using the Bloom Filter, if it does not exist it returns "true" otherwise it does a query on the database to check the existence as the filter may answer that the username is not available even when it is due to hash function collisions.
I added a new method in the controller user.js:
export const checkUsernameAvailability = async ({username}) => {
log.info('Controller::users::checkUsernameAvailability', {username})
const available = await User.checkUsernameAvailability(username)
return {
available
}
}And I added the new route in router.js:
import {authenticate, routeToFunction} from "./middlewares.js";
import {checkUsernameAvailability} from "./controllers/user.js";
router.get('/check-username', authenticate, routeToFunction(checkUsernameAvailability));
export default router;POST /user/username
I added the update method in the User.js class:
static update = async (id, params_to_update) => {
log.info('Model::User::update', {id, params_to_update})
if (params_to_update.length === 0) {
throw new APIError422('At least one parameter must be provided to update the user.')
}
const {username} = params_to_update
const params = []
let query_sql = `
update users
set
`;
if (username) {
query_sql += ` username = ?`;
params.push(username);
}
query_sql += ` where id = ?`;
params.push(id);
await query(query_sql, params);
const user = await User.get({id})
return user
}I added a new method in the controller user.js:
export const setUsername = async ({username}) => {
log.info('Controller::users::setUsername', {username})
const user_id = asyncStorage.getStore().user_id;
const user = await User.get({id: user_id})
if (user.username) {
throw new APIError422('Username already set')
}
const available = await User.checkUsernameAvailability(username)
if (!available) {
throw new APIError422('Username already taken')
}
const updated_user = await User.update(user_id, {username})
await UsernameBloomFilter.add(username)
return updated_user
}if the username is available I update the user via the update method and the bloom filter via the add method.
Finally, I added the new route:
import {authenticate, routeToFunction} from "./middlewares.js";
import {checkUsernameAvailability, setUsername} from "./controllers/user.js";
router.get('/check-username', authenticate, routeToFunction(checkUsernameAvailability));
router.post('/user/username', authenticate, routeToFunction(setUsername));
export default router;⭐️ User interface
I enhanced the project's UI for authentication with Magic Link to allow configuring a username using the Bloom Filter.
This helps decrease the database load by checking if the username is present in the filter first. If it's found, a database query is triggered to prevent a false positive.
You can try at: https://magic-link-auth.bubbleapps.io/version-test/

🌟 Top lectures of the week
Done is better than Perfection
How Disney+ Scaled to 11 Million Users on Launch Day
How I Setup my Terminal for Ultimate Productivity
And that’s it for today! If you are finding this newsletter valuable, consider doing any of these:
🍻 Read with your friends — Implementing lives thanks to word of mouth. Share the article with someone who would like it.
📣 Provide your feedback — We welcome your thoughts! Please share your opinions or suggestions for improving the newsletter, your input helps us adapt the content to your tastes.
💬 Chat with me — If you have any doubts or curiosity, please write to me, I will be happy to answer you!
I wish you a great day! ☀️
Marco
Aren't bloom filters built in redis already ?
https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/
Great article, Marco.
Bloom filters have been very useful in many complex problems but the simplicity you had in your explanation is very elegant.